I’m virtually attending ICLR 2021 so I can tip my toes back into ML. Here are a few papers I found interesting on my exploration on day 1 (some of them appear as posters or oral sessions on later days):
The Traveling Observer Model 🎠
This approach enables multi-task learning by using the same model for all tasks.
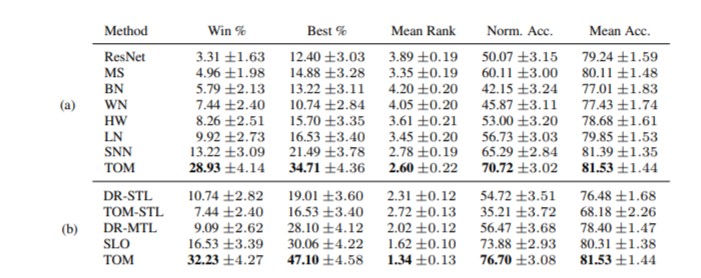
🤩 Result On the UCI 121 dataset which has a set of 121 classification tasks, TOM performs very well compared to other approaches.
Key Points
- For each task, a Variable embedding vector \(\mathbf{z}\) is used for both input and output to project tasks to the same space. An encoder takes in \(x_i, \mathbf{z_i}\) where \(\mathbf{z_i}\) is input VE and a decoder uses the encoding and \(\mathbf{z'_i}\) to spit output \(y_i\). In this scheme, encoder and decoder weights as well as \(\mathbf{z_i}\) and \(\mathbf{z'_i}\) are learned. The pytorch forward pass is illustrative

- It is discovered that VEs for inputs of same task exhibit regular structure, often falling on a 1D or 2D manifold. If the inputs fall in a semantic sequence, then a spatial sequence emerges for the corresponding VEs 🆒
Next Steps I’m curious to see if this approach can be used for learning on Multimodal data. There’s a great deal of shared knowledge for such inputs in those scenarios.
Dataset Inference (Or how to spot Model thiefs)
Coming Soon
>> Home